Microsoft recently released an update which causes DFSRS.exe CPU usage to hit 100%.
https://support.microsoft.com/en-us/kb/3156418
I wrote about this problem on the following blog post:
http://clintboessen.blogspot.com.au/2016/07/dfsr-service-100-cpu-usage.html
Since installing this update and removing this update, one of our spoke servers failed to replicate back to the primary hub server. All data from the spoke server replicated correctly to the hub, however data from the hub was not propagating down to the spoke.
The backlog count continued to increase.

DFSR Hotfix https://support.microsoft.com/en-us/kb/2996883 was not installed on the affected hub server.
We knew there was no issue with our hub server as this was replicating successfully to 16 other DFSR spoke servers.
On the affected spoke server, I worked with the Directory Services team from Microsoft who made the following changes to the Network Interface.
C:\Windows\system32>netsh int tcp set global chimney=disabled
Ok.
C:\Windows\system32>netsh int tcp set global rss=disabled
Ok.
C:\Windows\system32>netsh int ip set global taskoffload=disabled
Ok.
C:\Windows\system32>netsh int tcp set global autotuninglevel=disabled
Ok.
C:\Windows\system32>netsh int tcp set global ecncapability=disabled
Ok.
C:\Windows\system32>netsh int tcp set global timestamps=disabled
Ok.
C:\Windows\system32>netsh advf set allp state off
Ok.
Microsoft then disabled the following Offload features on the HP Network Interface card on the spoke server:

https://support.microsoft.com/en-us/kb/3156418
I wrote about this problem on the following blog post:
http://clintboessen.blogspot.com.au/2016/07/dfsr-service-100-cpu-usage.html
Since installing this update and removing this update, one of our spoke servers failed to replicate back to the primary hub server. All data from the spoke server replicated correctly to the hub, however data from the hub was not propagating down to the spoke.
The backlog count continued to increase.
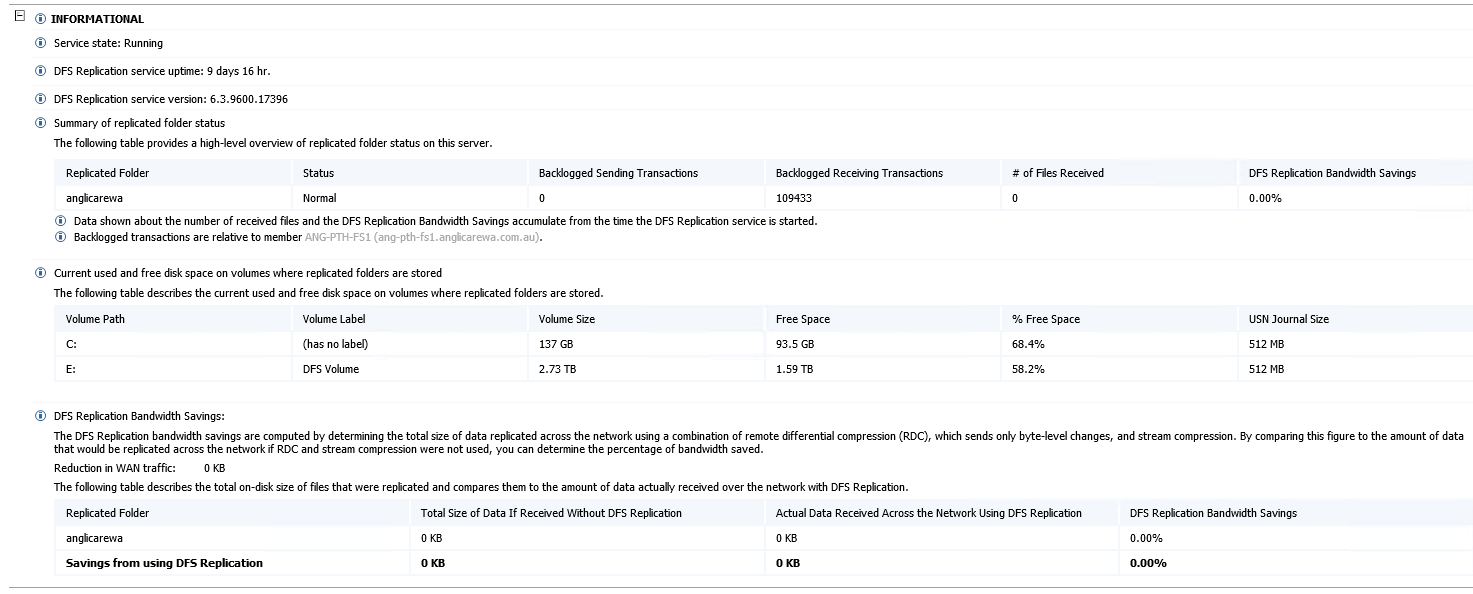{kind=link}

DFSR Hotfix https://support.microsoft.com/en-us/kb/2996883 was not installed on the affected hub server.
We knew there was no issue with our hub server as this was replicating successfully to 16 other DFSR spoke servers.
On the affected spoke server, I worked with the Directory Services team from Microsoft who made the following changes to the Network Interface.
C:\Windows\system32>netsh int tcp set global chimney=disabled
Ok.
C:\Windows\system32>netsh int tcp set global rss=disabled
Ok.
C:\Windows\system32>netsh int ip set global taskoffload=disabled
Ok.
C:\Windows\system32>netsh int tcp set global autotuninglevel=disabled
Ok.
C:\Windows\system32>netsh int tcp set global ecncapability=disabled
Ok.
C:\Windows\system32>netsh int tcp set global timestamps=disabled
Ok.
C:\Windows\system32>netsh advf set allp state off
Ok.
Microsoft then disabled the following Offload features on the HP Network Interface card on the spoke server:
- IPv4 Large Send Offload
- Large Send Offload V2 (IPv4)
- Large Send Offload V2 (IPv6)
- TCP Connection Offload (IPv4)
- TCP Connection Offload (IPv6)
- TCP/UDP Checksum Offload (IPv4)
- TCP/UDP Checksum Offload (IPv6)
After disabling these components of the network interface card and restarting the DFS Replication service, the backlog count from the hub server to the spoke server slowly started decreasing.
TCP offload engine is a function used in network interface cards (NIC) to offload processing of the entire TCP/IP stack to the network controller. By moving some or all of the processing to dedicated hardware, a TCP offload engine frees the system's main CPU for other tasks
This is dummy text. It is not meant to be read. Accordingly, it is difficult to figure out when to end it. But then, this is dummy text. It is not meant to be read. Period.
ConversionConversion EmoticonEmoticon